Your monitoring tool fires 200 alerts at 3AM. Half are noise. The real issue is buried on page four. The on-call engineer wakes up, spends 45 minutes correlating logs across five dashboards, and finally finds a database connection pool that exhausted itself. AIOps fixes this — AI filters the noise, finds the root cause, and tells you exactly what broke and why before your phone even rings.
This guide covers what AIOps actually is, how it works at a technical level, the best tools in 2026, and how to set up a basic implementation with open source tools today.
What is AIOps?
AIOps stands for Artificial Intelligence for IT Operations. It is the application of machine learning, big data analytics, and automation to IT operations — specifically to monitoring, event correlation, anomaly detection, and incident response.
The definition from Gartner: “AIOps platforms use big data, modern machine learning and other advanced analytics technologies to directly and indirectly enhance IT operations.”
In practice, AIOps means your monitoring system gets smarter over time. It learns what normal looks like for your systems. When something deviates from normal, it finds it — even if there is no explicit threshold alert configured.
How it differs from traditional monitoring:
Traditional monitoring: you set thresholds. CPU > 80% = alert. This generates enormous noise because normal CPU spikes during deployments, batch jobs, and traffic peaks all look the same as an actual problem.
AIOps: ML models learn your traffic patterns, deployment schedules, and historical incidents. A CPU spike at 2PM on a Tuesday during a known batch job is not an alert. An unusual CPU spike at 2AM on a Sunday that correlates with increased database errors and a memory leak pattern IS an alert — and it comes with context.
The shift from reactive to predictive:
Traditional monitoring tells you something broke. AIOps tells you something is about to break — often 30–60 minutes before the user impact. That window is the difference between a graceful failover and a production outage.
The Problem AIOps Solves
Alert fatigue is the defining problem of modern operations. Large production systems routinely generate thousands of alerts per day. Studies consistently show that 60–80% of these alerts are noise — false positives, duplicates, or symptoms of the same root cause. Engineers tune them out. The critical alert gets buried.
Manual log analysis does not scale. When an incident fires at 3AM, an engineer has to SSH into servers, grep through logs, correlate timestamps across services, and form a hypothesis about root cause. In a microservices environment with 50+ services, this is genuinely hard. It takes the wrong engineer 2 hours. It takes the right engineer 20 minutes. AIOps makes every engineer the right engineer.
Missed cross-system patterns are invisible to humans. A subtle memory leak in Service A causes connection pool exhaustion in Service B which causes timeouts in Service C which causes cascading failures across the entire platform. The human brain can trace this chain retrospectively. AIOps finds it in real time.
On-call burnout is driving engineers out of the field. Being woken up for alerts that turn out to be nothing — repeatedly — damages morale and increases attrition. AIOps dramatically reduces meaningless pages.
How AIOps Works: The 4 Layers
Layer 1: Data Ingestion
AIOps starts with data — all of it. Metrics from Prometheus, CloudWatch, Datadog. Logs from your applications, infrastructure, and cloud services. Traces from distributed tracing systems like Jaeger or AWS X-Ray. Events from your CI/CD pipeline, deployment systems, and change management.
The more data sources you feed in, the better the correlation engine becomes.
Layer 2: Anomaly Detection
Machine learning models run continuously against your telemetry data. These models use techniques including:
- Seasonal decomposition — separating trend, seasonality, and residual components to find true anomalies against baseline
- Isolation forests — detecting outlier behavior in high-dimensional metrics
- LSTM neural networks — time-series prediction to flag deviations from expected patterns
The key: these models learn your systems, not generic thresholds. Your morning traffic spike is normal. An identical spike at 3AM is anomalous.
Layer 3: Root Cause Analysis
This is where AIOps becomes genuinely valuable. When anomalies are detected across multiple services simultaneously, the correlation engine asks: what is the common cause? It cross-references:
- Deployment events (was something deployed recently?)
- Change management records
- Network events
- Database query patterns
- Historical incident data
The output is not a list of symptoms — it is a probable root cause with confidence score and evidence.
Layer 4: Automated Response
For known incident patterns, AIOps can take automated action: auto-scaling the affected service, restarting a crashed pod, increasing connection pool limits, or routing traffic away from a degraded region.
For unknown patterns, AIOps assembles the incident context, creates a structured summary, and sends it to the on-call engineer — who arrives at their laptop already knowing what broke and why.
AIOps in Practice: Real Scenarios
Scenario 1: CPU Spike at 2AM
Old way: PagerDuty fires at 2:07AM. Engineer wakes up, logs in, checks CloudWatch, opens Datadog, correlates with application logs, eventually finds a scheduled batch job that was moved to 2AM by a developer and now conflicts with a nightly backup. 45 minutes of investigation, nobody slept well.
AIOps way: ML model sees the CPU spike pattern, cross-references with the deployment history, finds the new batch job scheduling entry committed 3 days ago. Auto-creates an incident with the root cause already identified. Posts a Slack message: “Scheduled batch job nightly-report-generator is conflicting with nightly backup at 02:00. Recommend rescheduling to 03:30. Similar incident: INC-2847 from last month.” Nobody is paged. In the morning, someone fixes the schedule.
Scenario 2: Database Slowdown
Old way: Users report the app is slow. Backend team says the DB is fine. DBA says the app is sending bad queries. Frontend team says they didn’t change anything. Three teams pointing fingers for 2 hours while the outage continues.
AIOps way: Distributed traces show query latency increased 400ms starting at 14:23:17. Correlation engine finds a deployment at 14:21:05 that changed a query in the user search service. Incident ticket is auto-created with the offending deployment SHA, the specific query that changed, and a recommendation to roll back. Total time from first slow query to root cause identification: 90 seconds.
Best AIOps Tools in 2026
Datadog
What it does: Full-stack observability with Watchdog AI engine for automatic anomaly detection across metrics, logs, and traces. Best for: Organizations wanting a single pane of glass across cloud, containers, and applications. Free tier: 5 hosts, 1-day log retention. Pricing: From $15/host/month.
Dynatrace
What it does: Davis AI engine provides full root cause analysis with causal chain discovery. Deep Kubernetes and cloud-native support. Best for: Large enterprises with complex microservices environments. Free tier: 15-day trial. Pricing: Consumption-based, from $0.08/hour/host.
New Relic
What it does: AI-powered observability platform with anomaly detection and intelligent alerting. Best for: Teams wanting a generous free tier to start. Free tier: 100GB/month data ingest, unlimited users. Pricing: Pay-as-you-go above free tier.
AWS CloudWatch Anomaly Detection
What it does: Built-in ML-based anomaly detection for CloudWatch metrics. Best for: AWS-heavy shops that want native integration without a separate tool. Free tier: Included in CloudWatch pricing. Pricing: $0.10 per alarm with anomaly detection per month.
Prometheus + Grafana + ML (Open Source)
What it does: You build it yourself using Prometheus for metrics, Grafana for visualization, and community ML extensions for anomaly detection. Best for: Teams with engineering capacity who want full control and zero licensing cost. Cost: Free.
Setting Up Basic AIOps with Prometheus + Grafana
Here is a working Prometheus alerting rule that uses statistical anomaly detection:
# prometheus-anomaly-detection.yaml
groups:
- name: anomaly_detection
rules:
- alert: CPUAnomalyDetected
expr: |
abs(
rate(node_cpu_seconds_total{mode!="idle"}[5m])
- avg_over_time(rate(node_cpu_seconds_total{mode!="idle"}[5m])[1h:5m])
)
> 2 * stddev_over_time(rate(node_cpu_seconds_total{mode!="idle"}[5m])[1h:5m])
for: 5m
labels:
severity: warning
annotations:
summary: "CPU anomaly detected on {{ $labels.instance }}"
description: "CPU usage has deviated more than 2 standard deviations from the 1-hour baseline."
- alert: RequestRateAnomaly
expr: |
abs(
rate(http_requests_total[5m])
- avg_over_time(rate(http_requests_total[5m])[1h:5m])
)
> 3 * stddev_over_time(rate(http_requests_total[5m])[1h:5m])
for: 3m
labels:
severity: critical
annotations:
summary: "Abnormal request rate on {{ $labels.service }}"This uses standard deviation over a rolling 1-hour baseline to detect anomalies. It adapts automatically to your traffic patterns — no manual threshold tuning required.
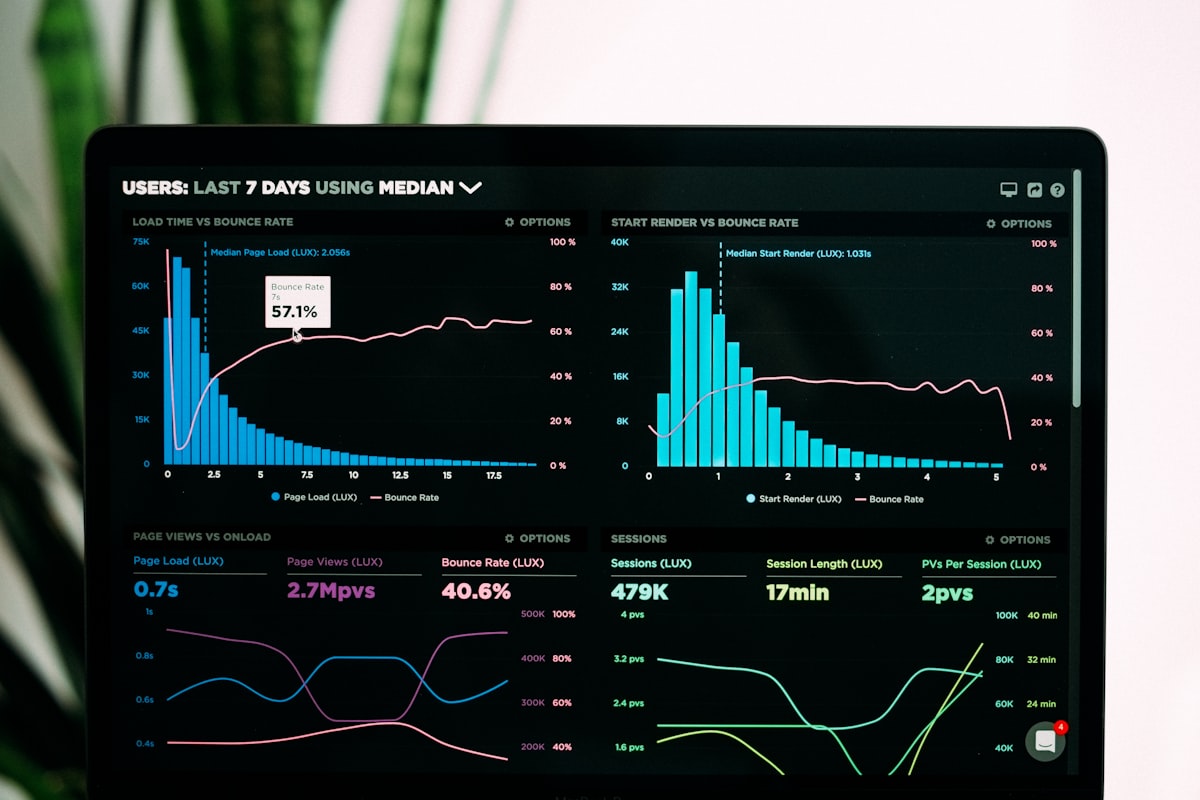
 AIOps dashboards correlate alerts across services to identify root cause instantly
AIOps dashboards correlate alerts across services to identify root cause instantly
Building an AI Incident Response Runbook
Here is a complete automated incident response workflow using Python and the Claude API:
import anthropic
import boto3
import requests
from datetime import datetime, timedelta
client = anthropic.Anthropic()
cloudwatch = boto3.client('cloudwatch', region_name='us-east-1')
logs_client = boto3.client('logs', region_name='us-east-1')
def get_recent_logs(log_group, minutes=30):
end_time = int(datetime.now().timestamp() * 1000)
start_time = int((datetime.now() - timedelta(minutes=minutes)).timestamp() * 1000)
response = logs_client.filter_log_events(
logGroupName=log_group,
startTime=start_time,
endTime=end_time,
filterPattern="ERROR"
)
return [e['message'] for e in response.get('events', [])]
def analyze_incident(service_name, alert_details):
logs = get_recent_logs(f"/aws/ecs/{service_name}")
log_sample = "\n".join(logs[:50]) # Last 50 error logs
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1000,
messages=[{
"role": "user",
"content": f"""Analyze this production incident:
Alert: {alert_details}
Service: {service_name}
Recent error logs:
{log_sample}
Provide:
1. Most likely root cause (1-2 sentences)
2. Immediate remediation steps (numbered list)
3. Severity: CRITICAL / HIGH / MEDIUM
4. Estimated user impact"""
}]
)
return message.content[0].text
def post_to_slack(webhook_url, message):
requests.post(webhook_url, json={"text": message})
# Example usage
if __name__ == "__main__":
analysis = analyze_incident(
service_name="payment-api",
alert_details="High error rate: 500 errors spiking to 45% at 14:23 UTC"
)
slack_message = f":rotating_light: *Incident Analysis*\n\n{analysis}"
post_to_slack("https://hooks.slack.com/your-webhook", slack_message)
ML models detect subtle performance degradation hours before it becomes an outage
 AIOps reducing 200 noisy alerts down to 1 actionable insight
AIOps reducing 200 noisy alerts down to 1 actionable insight
FAQ
What is AIOps and how does it work? AIOps applies machine learning to IT operations data — metrics, logs, and traces — to detect anomalies, correlate events, identify root causes, and automate responses. It works by learning your system’s normal behavior patterns and flagging meaningful deviations, rather than relying on manually configured thresholds.
Is AIOps replacing DevOps engineers? No. AIOps handles the repetitive, pattern-matching work of incident detection and initial diagnosis. It makes engineers faster and better-rested. The judgment calls — architecture decisions, novel incident types, business context — still require human expertise. AIOps amplifies engineers; it does not replace them.
What is the best AIOps tool for Kubernetes? Dynatrace has the deepest Kubernetes integration with its OneAgent and Davis AI engine. For open source, Prometheus + Grafana with anomaly detection rules is a solid starting point. New Relic also has strong Kubernetes support with a generous free tier.
How much does AIOps cost to implement? Open source (Prometheus + Grafana + custom ML rules): effectively free beyond engineering time. Commercial tools range from $15/host/month (Datadog) to $0.08/hour/host (Dynatrace). For a 20-host production environment, budget $300–1,000/month for commercial AIOps tooling.
Can I build AIOps with open source tools? Yes. Prometheus for metrics collection, Grafana for visualization, and statistical alerting rules (like the standard deviation example above) give you the foundation. For more sophisticated ML, Victoria Metrics Anomaly Detection is a free, open source anomaly detection tool built on top of Prometheus.
Conclusion
AIOps is not a future concept — it is running in production at every mature engineering organization today. The question is not whether to adopt it but how fast to move.
Start with the simplest win: implement statistical anomaly detection in your existing Prometheus setup using the rules shown above. That alone will reduce your alert noise by 40–60%. Then layer in automated incident analysis using the Claude API pattern, and you have a basic but real AIOps capability running in your infrastructure within a week.
Need help setting up AI-powered monitoring for your infrastructure? View our DevOps services →
Related: How to Build Claude AI Agents That Automate Your Infrastructure